Introduction
The usual take about the growth of code agents in tech teams includes two points: that the engineer’s productivity has increased by a factor of X using code agents, and that the bottleneck is now in the review and verification process.
As a result, the claim is that the bottleneck is in verification. By verification, people usually mean that code is generated but then needs to go through the human verification process for quality control. Since a machine can generate code faster than a human can read, PRs now accumulate in codebases faster than developers can review and merge them. There is a lot of talk about turning the full process agentic and automatic. This means that agents will write the code, and the agents will review the code using unit tests and integration tests.
This made me curious to understand how partially driven agentic development, where an engineer iterates with an agent compares to fully automatic agentic approaches. I was mostly interested to look at execution time and performance and readability of the code.
The Agentic Software Engineering: Different approaches
In the agentic way of engineering, I classify engineer’s different approaches into four distinct categories:
- Human code: Code that is generally written by the humans themselves with little or no interaction from an LLM or an agent.
- Agent-assisted: Engineers begin with the initial code written by themself. After that, engineers refines the code by the agent iteratively until they reach a solution.
- Human-in-the-loop: Unlike the previous case, engineers begin by writing a written prompt that describes the problem and provide no actual code. Thereafter, engineers keep refining prompts until a solution is accepted by the engineer.
- Fully Agentic: Engineers describe the problem with a single prompt, and let the agent solve the whole task completely by itself.
Using this categorization, I would like to see how choosing any of these categories will affect the final solution code generated and its performance and quality.
Use Case: Binary Search Tree
Let us show this by an example using Cursor’s Composer 2 as an agent. Assume we are building a simple Binary Tree Search (BTS) that accepts an array and builds a BTS from it. The Binary Tree Search (BTS) is a sorted tree-based data structure that you can insert an element to it. There is with only one rule: in each tree, the left (right) child of the root node has to have a value less (larger) than the root node. If you would like to know more about Binary Tree Search insertion, you can read GeeksforGeeks’ article about it.
Note that this problem is a known and easy problem for an agent like Composer 2, I decided to keep my interaction with the agent to max 3 interactions (prompts) to avoid overfitting. The code is also expected to show the tree in the prompt but I do not dig into this part of the function even though the printing function of the agentic code seemed unnecessary complex and redundant.
Below we compare different parts of the code. The human.py contains the primitive code I wrote myself and it is somewhat naive. The reason for this is that later on, in the Agent-assisted case, I wanted to give the agent a big chance to be able to improve the code. The file agent_fully_automated.py contains the fully agentic code and human_in_the_loop.py contains the human-in-the-loop case. The agent-assisted development code will follow in the last step as it is very similar to the human.py file. If you are curious about the prompt, the Appendix section at the bottom of this page includes these prompts.
So let us start with the basic parts. How are the nodes implementated?
# human.py
from typing import List, Optional
class Node:
def __init__(self, value: float,
parent: Optional["Node"] = None,
left_child: Optional["Node"] = None,
right_child: Optional["Node"] = None) -> None:
self.value = value
self.parent = parent
self.left_child = left_child
self.right_child = right_child
# agent_fully_automated.py
class Node:
__slots__ = ("val", "left", "right")
def __init__(self, val: int) -> None:
self.val = val
self.left: Node | None = None
self.right: Node | None = None
# human_in_the_loop.py
class Node:
__slots__ = ("val", "left", "right")
def __init__(self, val: int) -> None:
self.val = val
self.left: Node | None = None
self.right: Node | None = None
The human code includes a parent relationship for nodes whereas agents, Human-in-the-Loop (HITL) and agentic code include a more compact structure to the code without that property. Are there any abstractions for the Binary Search Tree in each code?
# human.py
class BinarySearchTree:
def __init__(self) -> None:
self.root : Optional[Node] = None
def insert(self, values: list[float]) -> None:
if self.root is None:
self.root = Node(values[0], None, None, None)
for value in values[1:]:
self.insert_recursive(self.root, value)
# agent_fully_automated.py
"""Defines no abstraction for a tree at all """
# human_in_the_loop.py
class BinarySearchTree:
def __init__(self, values: list[int] | None = None) -> None:
self.root: Node | None = None
if values:
for x in values:
self.insert(x)
def insert(self, val: int) -> None:
self.root = self._insert_recursive(self.root, val)
So far, I wanted to show the structure and the syntax difference between a human/agent/agent-assisted code even when it comes to the class definitions. Now let us focus on the main part of the code. How will the insertion logic will be implemented?
# human.py
def insert_recursive(self, node: Node, value: float) -> None:
if value < node.value:
if node.left_child is None:
node.left_child = Node(value, node, None, None)
return
else:
self.insert_recursive(node.left_child, value)
elif value > node.value:
if node.right_child is None:
node.right_child = Node(value, node, None, None)
return
else:
self.insert_recursive(node.right_child, value)
# human_in_the_loop.py
@staticmethod
def _insert_recursive(node: Node | None, val: int) -> Node:
if node is None:
return Node(val)
if val < node.val:
node.left = BinarySearchTree._insert_recursive(node.left, val)
else:
node.right = BinarySearchTree._insert_recursive(node.right, val)
return node
# agent_fully_automated.py
def insert_iterative(root: Node | None, val: int) -> Node:
"""Insert *val* with a loop (no recursion)"""
new = Node(val)
if root is None:
return new
cur = root
while cur is not None:
go_left = val < cur.val
child = cur.left if go_left else cur.right
if child is None:
if go_left:
cur.left = new
else:
cur.right = new
return root
cur = child
return root
In the Human-in-the-Loop scenario, the agent insists that writing the function in a recursive manner is easier to read, but decreases the performance. So the engineer accepts the implementation, after asking a question about this.
Now let us discuss the Agent-assisted case. The user has pasted the human code and asks the agent to improve the code with readability and performance in mind. The agent follows the original class definitions as with the human code, but then the insertion logic changes to a similar function to the Human-in-the-Loop case where the call is no longer recursive for better performance:
def insert(self, values: list[float]) -> None:
"""Insert every element in *values* (order preserved). Empty list is a no-op."""
for v in values:
self.insert_one(v)
def insert_one(self, value: float) -> None:
"""Insert a single value. Smaller → left; greater or equal → right (duplicates on the right)."""
new = Node(value)
if self.root is None:
self.root = new
return
node = self.root
while node is not None:
go_left = value < node.value
nxt = node.left_child if go_left else node.right_child
if nxt is None:
new.parent = node
if go_left:
node.left_child = new
else:
node.right_child = new
return
node = nxt
Evaluation (Systematic)
How do these different implementation compare with each other. In order to evaluate these solutions, I have looked at two different types of measures: performance and readability. For performance the focus has been mostly time and memory usage. For readability, given that I wrote the human code and I am partially biased, I used systematic measures that I can explain below.
Let us start with time and memory performance. Here, we perform insertion with arrays with different number of elements, n. For this, we are using get_traced_memory to show the peak traced memory that focuses on the traced objects during that window in the Python process. For time, we are just counting the time it takes to insert into the Binary Search Tree.
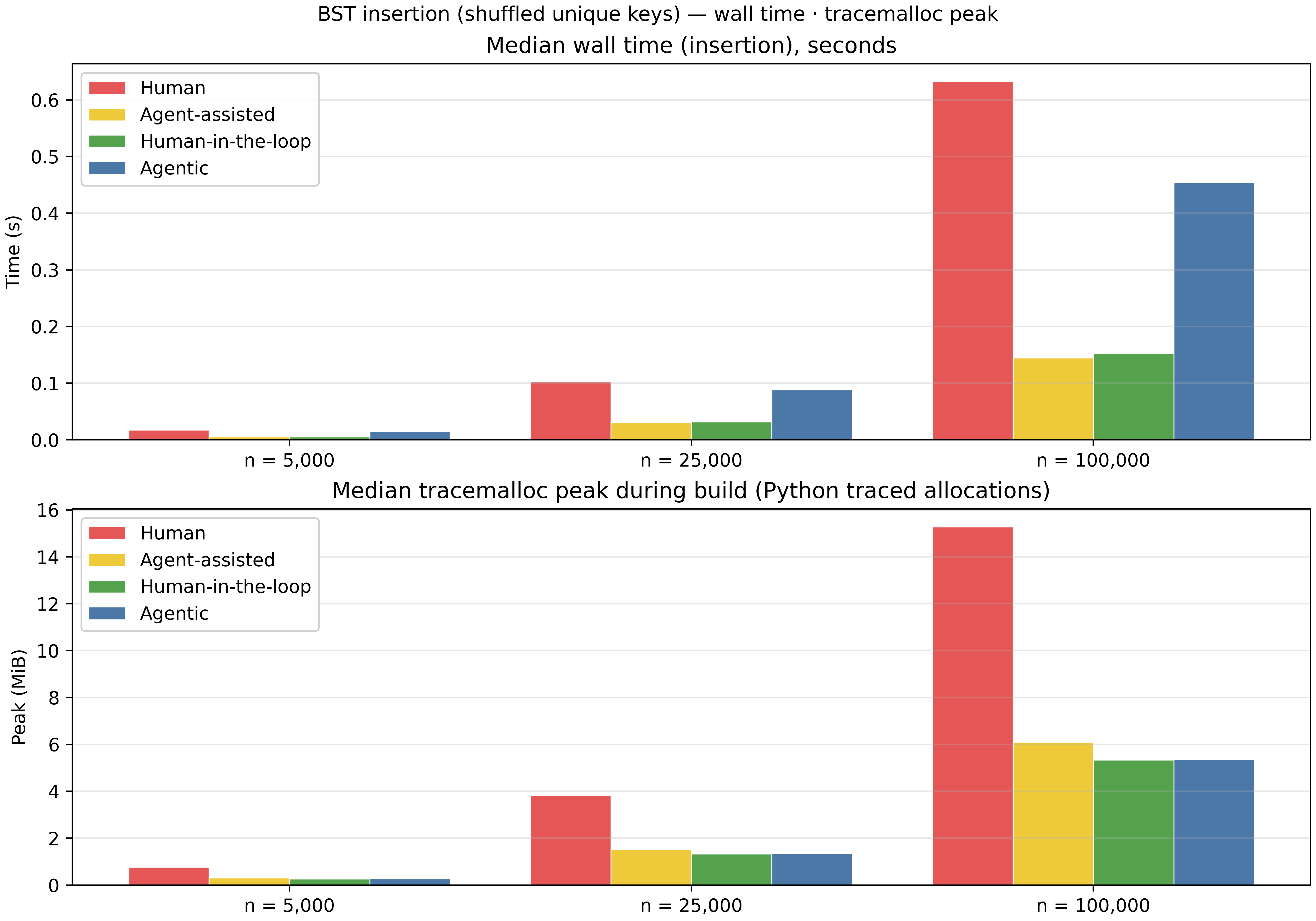
Evaluation of Time and Memory Usage
As you can see, we compared the performance with arrays up to 100000 elements. We see that the human written code performs well with smaller arrays but scales poorly with larger arrays, as the agent correctly explained in the human-in-the-loop and agent-assisted cases. However, surprisingly, the fully agentic code is also suffering with scale. Both agent-assisted and human-in-the-loop functions perform similar results when it comes to time, however, when it comes to memory usage, the human-in-the-loop code is performing equally well with the fully agentic function.
How about readability? As I mentioned earlier, I was aiming to find measures that can systematically define the readability, so let us begin there. I used the radon package and chose the following measures for readability:
- SLOC (Source Lines of Code): counts lines that count as “source” (roughly real code lines, not blank/comment-only). Higher means less readable.
- MaxCC (Max Code Complexity): gives a complexity number for each function/method (branches, loops, boolean conditions add paths). The max CC value is the worst value in that file. Higher means less readable.
- Avg CC: Average of radon’s complexity scores over all functions/methods it finds in the file. Higher means less readable.
- Maintainability Index (MI): Radon’s heuristic score (often discussed on a ~0–100 scale). It mixes size, complexity, and related signals into one number. In this blogpost, we choose the default MI value Radon provides. Higher, more readable.
- Nest: Deepest nesting of if / for / while / with / try / match inside each other. Higher means less readable.
Given that some measures have an inverse relationship with readability, I decided to rank different implementations and unify these so that larger rank means more readability.
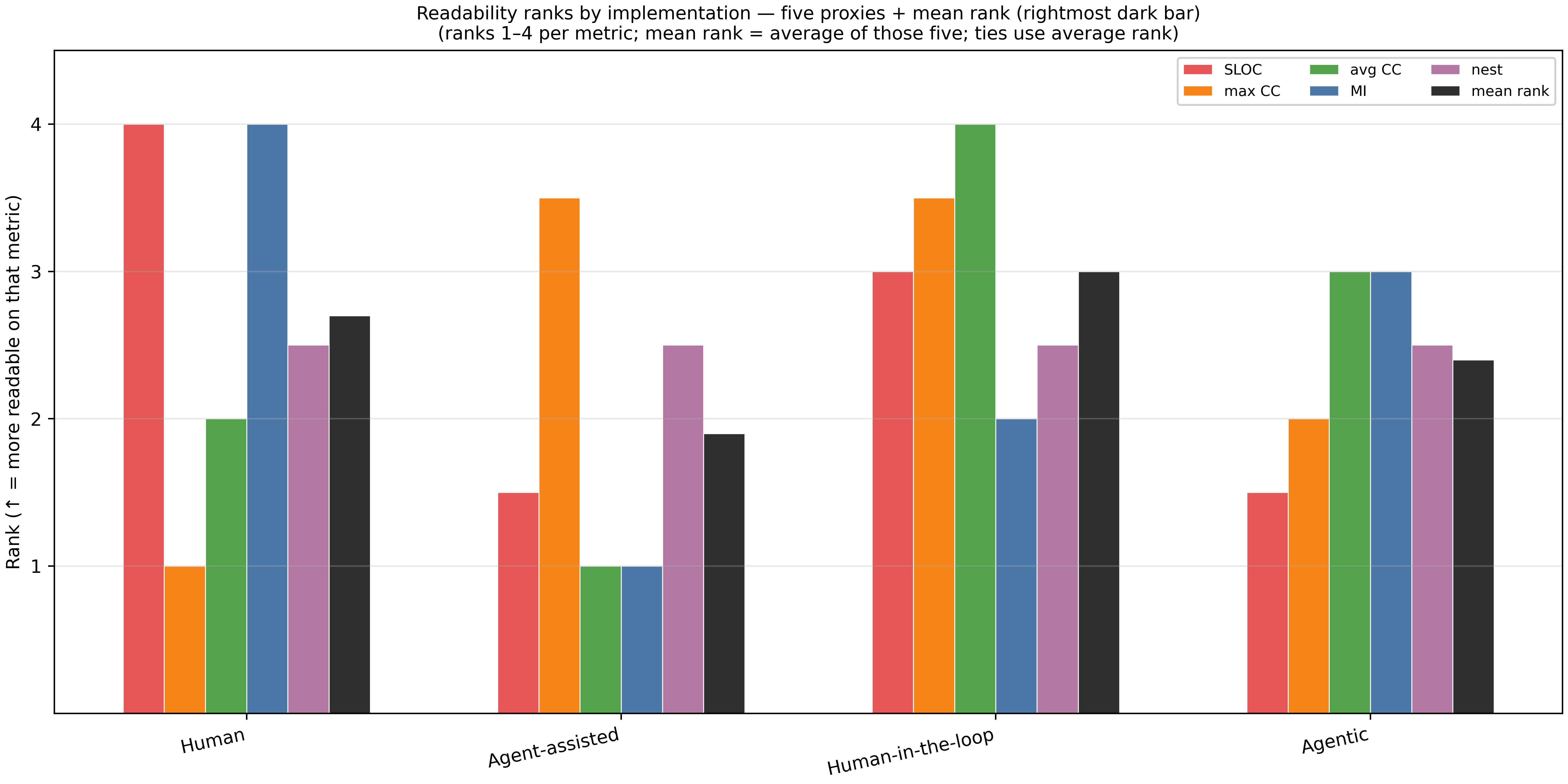
Evaluation of Readability
The chart shows each measure and also an average rank across measures. As we can see, the human-in-the-loop approach still performs best on average across all metrics. Note that the human code performs best with Code Complexity measures as it includes few lines compared to the other approaches.
Conclusion
One of the key observations I had was that the syntax of fully agentic code was very verbose and hard to read and understand. Composer 2 also did not include an abstraction for nodes, and it felt very machine-like.
Another observation was the similar performance of agent_assisted and human_in_the_loop approaches, given that the problem is rather easy for an agent like Composer 2 which is a limitation of our analysis. In the end, the human_in_the_loop performed slightly better in both performance and readability. Another followup blogpost is to pick a problem that is harder to describe by prompts, and see their difference.
I also saw that the solution provided by agent_assisted and human_in_the_loop were very limited to the local context. Once the code is generated, the improvements seem to be very incremental. I was expecting the agent to provide some drastic re-write or re-formulation of the human code, but that did not happen.
Another limitation of this study was that I only looked at the performance of one agent: Composer 2. It would be interesting to see how other code agents will perform for this task or maybe another more complicated problem.
One final conclusion I had was based on my analysis, we are not there for the fully agentic process in software engineering. One main constraint of this is that the output of this process is too tightly coupled with the prompt an engineer writes and the choice of the agents.
Final Words
When I use code agents in my daily work or in this blogpost, I feel a bit concerned. One crucial aspect of software engineering has always been the growth of the engineers. Before LLMs, software engineers used forums like Stack Overflow to learn collaboratively. Reviewing multiple answers, helping others, and reflecting on solutions provided deep learning. Engineers began by writing imperfect code, learning from debugging, and iteratively improving solutions.
Agent-assisted development risks turning engineers into passive consumers of solutions provided by a black-box thinker. Software engineers may end up relying on the generated code without developing the reasoning skills needed to solve new problems independently. During the 5/6 hours I spent developing this case and analyzing the results, I felt I could have learned more about BTS and its implementations with the same amount of time at hand but no agents. Agentic development is time consuming, since you have to read all these generated prompts, but sometimes less giving.
And I have another concern. You cannot make someone a distinguished author by handing them the first draft of Harry Potter. They might edit the draft or add subplots, but the process of becoming J.K. Rowling — developing skill and intuition — cannot be bypassed. Similarly, engineers must engage deeply with problems and solutions to truly grow.
In this specific analysis, I felt like using the agent, I will never know the possible alternatives another developer would implement the insertion code of a BTS and that felt a bit disheartening to be honest.
Acknowlegment
Special thanks to Mattias Lundberg for reading the first draft of this blogpost.
Appendix: Prompts
In this section, prompts I used for this experiment using Composer 2 are mentioned. As I wrote before, I chose to include max 3 interactions in each case to avoid bias. I am sure if I could keep asking the changes in numerous number of interaction loops, it would eventually get the code as I wanted but also the analysis would be very biased.
Agent-assisted
Prompt: User Pasted human code + Can you improve this code with regards to performance while keeping it as readable as possible?
Agent removes the recursive function calling and adds a while True loop with pointers to nodes. Prompt 2: Why did you not keep the insertion function recursive? Agent: Due to performance concerns.
Human-in-the-loop
Prompt: Can you include a class for the BTS itself?
Agents makes changes Prompt 2: This insertion function is a bit complicated as we speak since you are not calling it recursive, can we get away these
while Trueloops can you make it another way? Agent answers that recursive function will sacrifice too much of the performance. The engineer stops and keeps the code as final.
Fully agentic
Prompt: I want you to write a simple Binary Search Tree function In Python that accepts an array and can insert the elements into the array and prints a viz of the tree in the prompt line. Don’t look at the other files and any other resources in this repository. Just implement it from your own context here. The BTS needs to accept an array and build the tree. Consider readability and performance at the same time and make sure the code runs correctly with an input.
Agent answers with the code and a
___main__function to run the code.
Appendix 2: Code
The full code for the article is on: my Github repository.